


Introduction
Self-hosting your own ChatGPT is an exciting endeavor that is not for the faint-hearted. This is a great adventure for those seeking greater control over their data, privacy, and security. By self-hosting, you retain ownership and maintain the peace of mind that comes with knowing your conversations aren't being stored on third-party servers.
I will be introducing you to Ollama, which is an open-source application that allows you to run Large Language Models locally. Ollama gives you the ability to utilize MacOS, Windows, and Linux for your artificial intelligence endeavors. You can either host this locally using the applications or install script, or we can utilize my favorite method which is Docker.
To interact with our Ollama instance, we are going to spin up an Open WebUI container that will allow us to use a web browser to communicate and share files as it is designed to work with LLMs.
Self-hosting Ollama and these models requires significant computational power. Without the proper hardware, performance may be degraded, causing undue stress to your current system. Linux environments usually perform the best, however, it is compatible with Windows and MacOS.
You should also be aware that when using Docker Desktop, functionality may be limited due to the virtualization technologies, and on MacOS Docker Desktop doesn't fully support GPU pass-through.
Prerequisites
- Compatible hardware
- Internet connection
- Docker Installed
Run Ollama with Docker
This is a straightforward process, read the documentation for the specific GPU you have (NVIDIA or AMD) and use the correct container command. Otherwise, you can use the default command which will utilize the CPU and RAM. I don't know the true specs needed, but those in the community have suggested a minimum of four-core CPU and 4 gigabytes of RAM.
Intel GPUs are not currently supported, however, there are a few GitHub issues that have been posted about support. Looks like they are experimenting with it and support could come soon for Intel GPUs.
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
To run a model locally and interact with it you can run the docker exec command. If you use -it this will allow you to interact with it in the terminal, or if you leave it off then it will run the command only once.
If you want to run llama2 you can use this command to download and interact with it, when done you can use Control+D to exit.
docker exec -it ollama ollama run llama2
In my case, I want to use the mistral model
docker exec -it ollama ollama run mistral
Run Ollama with the Script or Application
If you don't want to run Ollama using Docker, you can install it using the proper application.
MacOS
To serve on all interfaces with MacOS, make sure the app isn't running and run the following command. You will need to detach from the session if you want to use it remotely. Referring to this GitHub issue. This allows you to connect with external applications like Open WebUI. You can also utilize Docker Desktop on the same machine.
OLLAMA_HOST=0.0.0.0 ollama run mistral
OLLAMA_HOST=0.0.0.0 ollama run llama2
# Control + D to detatch from the session and that should allow you to access it remotely.
Run Open WebUI
Straight from the GitHub project documentation, all we need to do is run this Docker command. Make sure you aren't already utilizing port 3000, if so then change it. Now of course, if you are running this on another server then you need to read both project's documentation further on how to access it.
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
If you chose to run Ollama outside of docker you may need to run this command and adjust your port information in your URL. This comes from the troubleshooting section of Open WebUI.
docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
After running the command if you navigate to http://ip:3000 you will be greeted with a login page. Here you can register for an account.
After you sign in, you can select the model we downloaded before and get started. If you want to select another model from the directory, you can add it, and the application will do the rest.
Reverse Proxy
If you have followed my previous guide on setting up Docker then you will know that we are using NGINX Proxy Manager. You can publish this outside of the network, and you can disable sign-ups once you get logged in.
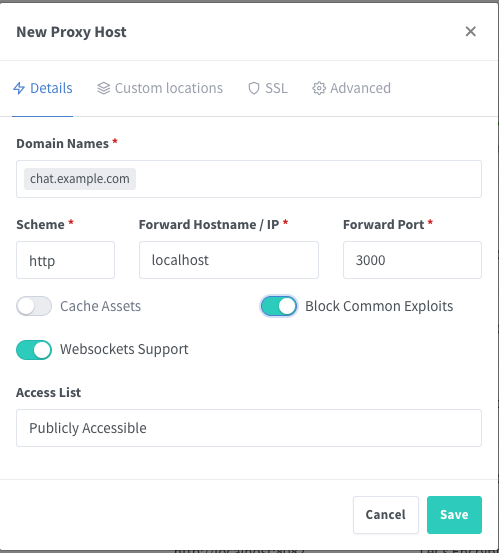
Go ahead and set your SSL certificate as well.
Conclusion
While ChatGPT and its alternatives offer productivity enhancements and knowledge expansion, they may not always meet security requirements. Self-hosting with Ollama provides a secure environment, ensuring data privacy and ownership. This versatile platform, available on multiple platforms including MacOS, Windows, and Linux, is currently limited to AMD and NVIDIA hardware but has Intel support under development. It's important to note that the choice of hardware significantly impacts performance.
By choosing to self-host with Ollama, you gain access to a more extensive range of projects and automation opportunities. In the spirit of exploration and continuous learning, I will be creating more articles as I delve deeper into this exciting technology. Encouraging readers to experiment and adapt to new security measures is essential for maintaining a proactive digital stance.
Full Disclosure
Most of this article is comprised of facts and opinions. The featured background image was created by andyoneru and is available on Unsplash. I added a blur and a gradient overlay with some text. The following images have been pulled or screenshotted from the respective websites/applications. I do not own this content.





